

Il sottile equilibrio tra vecchie tecniche e nuove frontiere del Machine Learning
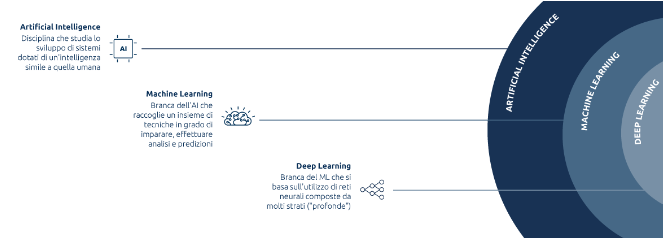
Artificial Intelligence, Machine Learning e Deep Learning: una matrioska di termini
di Simone Eandi, AI Engineer di Intesa, a Kyndryl Company

L’Artificial Intelligence (AI) è al centro dell’attenzione in questo momento, ma nei vari media vengono spesso usati, in maniera intercambiabile, termini come Machine Learning, Deep Learning o Reti Neurali. Ma sono davvero dei sinonimi? Ce ne parla in questo articolo Simone Eandi.
![]()
In questo articolo scoprirai:
Il termine Artificial Intelligence, utilizzato sin dagli anni ‘50, si riferisce alla disciplina che si occupa di sviluppare sistemi computerizzati in grado di simulare il comportamento umano con lo scopo di automatizzare attività tipicamente svolte da un esseri umani.
Nonostante i computer offrano la possibilità di automatizzare una vasta quantità di attività, storicamente si sono confrontati con una limitazione significativa: la necessità di essere programmati attraverso istruzioni esplicite e dettagliate. Per compiti anche apparentemente semplici questo processo è lungo, tedioso e poco flessibile. Sarebbe auspicabile che la macchina fosse in grado di apprendere con un certo livello di autonomia. Questo è esattamente quello di cui si occupa Machine Learning: sviluppare sistemi intelligenti in grado di apprendere in modo autonomo.
Reti Neurali
La grande maggioranza dei modelli di Machine Learning moderni di cui sentiamo parlare sono stati sviluppati partendo da una rete neurale. Le Reti Neurali (Neural Networks in inglese) sono una particolare famiglia di modelli di ML caratterizzata da una struttura nodale. Ogni nodo rappresenta una piccola unità logica in grado di svolgere semplici attività sui dati che riceve. Unendo molti di questi nodi insieme si ottiene una rete in grado di svolgere operazioni estremamente complesse. I nodi sono organizzati in strati, o layers, ognuno dei quali elabora dei risultati a partire dai suoi input e li passa a quello successivo, e così via finché l’ultimo strato non produce il risultato finale.
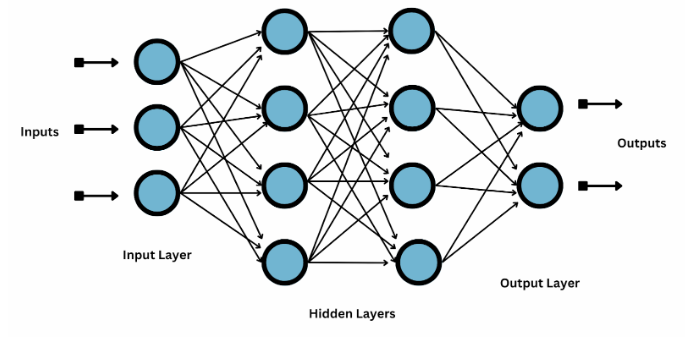
Durante il loro normale funzionamento, l’informazione segue uno specifico flusso che va dagli input agli output. Tuttavia, invertendo la direzione di tale flusso si può creare un feedback loop che permette ai nodi di apprendere autonomamente come comportarsi. Infatti, propagando dagli output verso gli input della rete la differenza tra il risultato desiderato per un determinato input e quello effettivamente prodotto, si può aggiornare il comportamento dei singoli nodi rendendo il loro comportamento più simile a quello atteso. Questa tecnica viene chiamata back-propagation ed è uno dei fondamenti dell’AI moderna.
Going Deep
A livello teorico le reti neurali erano ben note già nella seconda metà del ‘900. Tuttavia, quello che ne ha ostacolato la diffusione è stata la mancanza della potenza computazionale necessaria ad utilizzare reti neurali grandi abbastanza da produrre risultati utili.
Con l’esplosione delle Schede Video (GPU) negli anni 2000 si è scoperto che queste erano anche particolarmente adatte allo sviluppo di reti neurali, permettendo per la prima volta di addestrare delle reti con un numero estremamente elevato di nodi in tempi ragionevoli. È nata così la rivoluzione del Deep Learning, con un susseguirsi di risultati incredibili grazie all’utilizzo di reti neurali molto profonde (deep).
Le Reti Neurali non sono tutto
Sebbene dietro tutti i più grandi successi dell’AI in tempi recenti come riconoscimento facciale, comprensione del linguaggio naturale o generazione di testo o immagini ci sono delle Neural Networks, sorprendentemente queste non hanno ancora rimpiazzato completamente metodi di ML piú tradizionali.
Quando si lavora con immagini, video, testo o audio le reti neurali sono indiscutibilmente la famiglia di modelli più performanti. Tuttavia, la situazione cambia se si ha a che fare con dati tabulari. Su tali dati, infatti, metodi di ML tradizionali basati su alberi decisionali e gradient boosting dimostrano ancora performance superiori sia a livello di ricerca che in contesti industriali. Questi metodi sfruttano tanti piccoli modelli decisionali combinati in parallelo o in sequenza per generare il risultato finale e hanno il grosso vantaggio di essere molto più rapidi da sviluppare.
Un esempio di ML tradizionale in Intesa
All’interno del team IntesaLab, attualmente si stanno conducendo sperimentazioni mirate allo sviluppo di soluzioni avanzate per la previsione di abbandono del cliente, noto come “churn prediction”.
In questo contesto, l’obiettivo è anticipare la probabilità che un cliente interrompa la propria relazione con un servizio, utilizzando una serie di parametri informativi come età, durata del contratto, ecc. Considerando la struttura tabulare tipica di questi dati, è preferibile applicare metodologie di machine learning tradizionale, come i modelli basati su gradient boosting, piuttosto che reti neurali.
Conclusioni
Abbiamo visto che termini come Machine Learning (ML) e Deep Learning (DL) rappresentano ambiti di applicazione sempre più specifici nel campo dell’Intelligenza Artificiale (AI) e in particolare che Deep Learning consiste nell’utilizzo di Reti Neurali profonde. Visto il ruolo predominante che quest’ultime hanno assunto in campo AI, termini come ML, DL e AI vengono spesso utilizzati in maniera intercambiabile quando ci si riferisce a modelli basati su di esse. Tuttavia, è importante sottolineare che esistono anche metodi di Machine Learning differenti dalle Neural Networks che continuano ad avere un impatto significativo sul mercato.



